Chasing OpenStack idle connection timeouts
The original problem#
I’ve recently spent some time working on an OpenStack deployment. I ran into a
problem in which the compute service would frequently stop communicating
with the AMQP message broker (qpidd).
In order to gather some data on the problem, I ran the following simple test:
- Wait
nminutes - Run
nova boot ...to create an instance - Wait a minute and see if the new instance becomes
ACTIVE - If it works, delete the instance, set
n=2nand repeat
This demonstrated that communication was failing after about an hour, which correlates rather nicely with the idle connection timeout on the firewall.
I wanted to continue working with our OpenStack environment while testing
different solutions to this problem, so I put an additional interface on the
controller (the system running the AMQ message broker, qpidd, as well as
nova-api, nova-scheduler, etc) that was on the same network as our
nova-compute hosts. This would allow the compute service to communicate with
the message broker without traversing the firewall infrastructure.
As a workaround it worked fine, but it introduced a new problem that sent us down a bit of a rabbit hole.
The new problem#
With the compute hosts talking happily to the controller, I started looking at the connection timeout settings in the firewall. As a first step I cranked the default connection timeout up to two hours and repeated our earlier test…only to find that connections were now failing in a matter of minutes!
So, what happened?
By adding an interface on a shared network, I created an asymmetric route between the two hosts – that is, the network path taking by packets from the compute host to the controller was different from the network path taken by packets in the other direction.
In the most common configuration, Linux (and other operating systems) only have a single routing decision to make:
- Am I communicating with a host on a directly attached network?
If the answer is “yes”, a packet will be routed directly to the destination host, otherwise it will be routed via the default gateway (and transit the campus routing/firewall infrastructure).
On the compute host, with its single interface, the decision is simple. Since the canonical address of the controller is not on the same network, packets will be routed via the default gateway. On the controller, the situation is different. While the packet came in on the canonical interface, the kernel will realize that the request comes from a host on a network to which there is a more specific route than the default gateway: the new network interface on the same network as the compute host. This means that reply packets will be routed directly.
Asymmetric routing is not, by itself, a problem. However, throw in a stateful firewall and you now have a recipe for dropped connections. The firewall appliances in use at my office maintain a table of established TCP connections. This is used to reduce the processing necessary for packets associated with established connections. From the Cisco documentation:
By default, all traffic that goes through the security appliance is inspected using the Adaptive Security Algorithm and is either allowed through or dropped based on the security policy. The security appliance maximizes the firewall performance by checking the state of each packet (is this a new connection or an established connection?) and assigning it to either the session management path (a new connection SYN packet), the fast path (an established connection), or the control plane path (advanced inspection).
In order for two systems to successfully established a TCP connection, they must complete a three-way handshake:
- The initiating systems sends a
SYNpacket. - The receiving system sends
SYN-ACKpacket. - The initiating system sends an
ACKpacket.
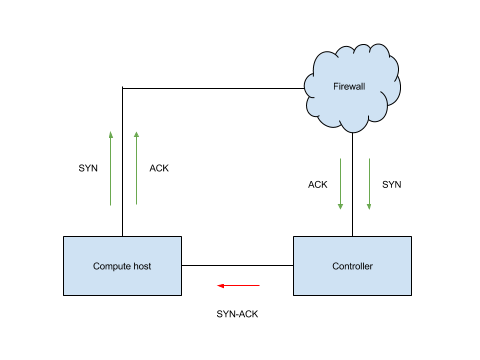
The routing structure introduced by our interface change meant that while the
initial SYN packet was traversing the firewall, the subsequent SYN-ACK
packet was being routed directly, which means that from the point of view of
the firewall the connection was never successfully established…and after 20
seconds (the default “embryonic connection timeout”) the connection gets
dropped by the firewall. The diagram below illustrates exactly what was
happening:
There are various ways of correcting this situation:
You could use the advanced policy routing features available in Linux to set up a routing policy that would route replies out the same interface on which a packet was received, thus returning to a more typical symmetric routing model.
You could use the tcp state bypass feature available in the Cisco firewall appliance to exempt AMQ packets from the normal TCP state processing.
I’m not going to look at either of these solution in detail, since this whole issue was secondary to the initial idle connection timeout problem, which has a different set of solutions.
Dealing with connection timeouts#
Returning to the original problem, what am I to do about the idle connection timeouts?
Disable idle connection timeouts on the firewall#
Once can disable idle connection timeouts on the firewall, either globally – which would be a bad idea – or for certain traffic classes. For example, “all traffic to or from TCP port 5672”. This can be done by adding a rule to the default global policy:
class-map amq
description Disable connection timeouts for AMQ connections (for OpenStack)
match port tcp eq 5672
policy-map global_policy
class amq
set connection random-sequence-number disable
set connection timeout embryonic 0:00:20 half-closed 0:00:20 tcp 0:00:00
While this works fine, it makes successful deployment of OpenStack dependent on a specific firewall configuration.
Enable Linux kernel keepalive support for TCP connections#
The Linux kernel supports a keepalive feature intended to deal with this
exact situation. After a connection has been idle for a certain amount of time
(net.ipv4.tcp_keepalive_time), the kernel will send zero-length packets every
net.ipv4.tcp_keepalive_intvl seconds in order to keep the connection active.
The kernel defaults to an initial interval of 7200 seconds (aka two hours),
which is longer than the default idle connection timeout on our Cisco
firewalls, but this value is easily tuneable via the
net.ipv4.tcp_keepalive_time sysctl value.
This sounds like a great solution, until you pay close attention to the tcp
man page (or the HOWTO document):
Keep-alives are only sent when the
SO_KEEPALIVEsocket option is enabled.
If your application doesn’t already set SO_KEEPALIVE (or give you an option
for doing do), you’re mostly out of luck. While it would certainly be possible
to modify either the OpenStack source or the QPID source to set the appropriate
option on AMQ sockets, I don’t really want to put myself in the position of
having to maintain this sort of one-off patch.
But all is not lost! It is possible to override functions in dynamic
executables using a mechanism called function interposition. Create a
library that implements the function you want to override, and then preload it
when running an application via the LD_PRELOAD environment variable (or
/etc/ld.so.preload, if you want it to affect everything).
It can be tricky to correctly implement function interposition, so I’m
fortunate that the libkeepalive project has already taken care of this. By
installing libkeepalive and adding libkeepalive.so to /etc/ld.so.preload,
it is possible to have the SO_KEEPALIVE option set by default on all sockets.
libkeepalive implements a wrapper to the socket system call that calls
setsockopt with the SO_KEEPALIVE option for all TCP sockets.
Here’s what setting up a listening socket with [netcat][] looks like before
installing libkeepalive:
$ strace -e trace=setsockopt nc -l 8080
setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
And here’s what things look like after adding libkeepalive.so to
/etc/ld.so.preload:
$ strace -e trace=setsockopt nc -l 8080
setsockopt(3, SOL_SOCKET, SO_KEEPALIVE, [1], 4) = 0
setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
Enable application level keepalive#
Many applications implement their own keepalive mechanism. For example, OpenSSH provides the ClientAliveInterval configuration setting to control how often keepalive packets are sent by the server to a connected client. When this option is available it’s probably the best choice, since it has been designed with the particular application in mind.
OpenStack in theory provides the qpid_heartbeat setting, which is meant
to provide a heartbeat for AMQ connections to the qpidd process. According to
the documentation, the default behavior of QPID clients in the OpenStack
framework is to send heartbeat packets every five seconds.
When first testing this option it was obvious that things weren’t working as documented. Querying the connection table on the firewall would often should connections with more than five seconds of idle time:
% show conn lport 5672
[...]
TCP ...:630 10.243.16.151:39881 ...:621 openstack-dev-2:5672 idle 0:34:02 Bytes 5218662 FLAGS - UBOI
[...]
And of course if the qpid_heartbeat option had been working correctly I would
not have experienced the idle connection timeout issue in the first place.
A post to the OpenStack mailing list led to the source of the problem: a
typo in the impl_qpid Python module:
diff --git a/nova/rpc/impl_qpid.py b/nova/rpc/impl_qpid.py
index 289f21b..e19079e 100644
--- a/nova/rpc/impl_qpid.py
+++ b/nova/rpc/impl_qpid.py
@@ -317,7 +317,7 @@ class Connection(object):
FLAGS.qpid_reconnect_interval_min)
if FLAGS.qpid_reconnect_interval:
self.connection.reconnect_interval = FLAGS.qpid_reconnect_interval
- self.connection.hearbeat = FLAGS.qpid_heartbeat
+ self.connection.heartbeat = FLAGS.qpid_heartbeat
self.connection.protocol = FLAGS.qpid_protocol
self.connection.tcp_nodelay = FLAGS.qpid_tcp_nodelay
If it’s not obvious, heartbeat was mispelled hearbeat in the above block of
code. Putting this change into production has completely resolved the idle
connection timeout problem.